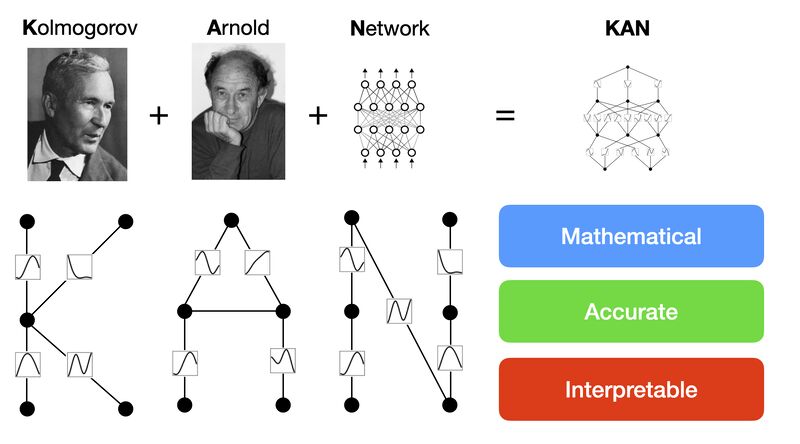
A New Contender in AI: Kolmogorov-Arnold Networks (KANs)
The race to improve AI efficiency just got more interesting. There’s a new potential LLM killer in town—Kolmogorov-Arnold Networks (KANs)—which promise 100X parameter efficiency compared to traditional neural network architectures.
If the research holds true, a 1B parameter KAN model could achieve the same accuracy as a 100B parameter classic Neural Net trained on the same dataset. This could revolutionize AI by significantly reducing computational costs, energy consumption, and infrastructure requirements, bringing LLM-scale intelligence to smaller, more accessible platforms.
How Are KANs Different?
Traditional neural networks operate using weighted sums and activation functions, adjusting the weights during training to optimize performance. In contrast, KANs introduce activation functions on the connections between nodes, which can be learned and adjusted dynamically.
This fundamental difference allows KANs to:
✅ Capture complex patterns while maintaining high precision.
✅ Be more efficient in terms of the number of parameters needed for accuracy.
✅ Adapt better to different types of data, potentially outperforming LLMs on structured learning tasks.
100X Parameter Efficiency, 10X Speed Advantage
KANs may be slower than traditional Multilayer Perceptrons (MLPs) of the same parameter size, running at 1/10th the speed. However, because KANs need far fewer parameters to achieve the same level of accuracy, they ultimately end up being 10X faster when operating at a fixed capability level.
This efficiency could change the game for AI applications where speed, cost, and resource constraints are key—especially in edge computing, small-device inference, and AI democratization.
Challenges and the Road Ahead
KANs sound promising, but the approach still has limitations:
- Scaling Issues: Current research has only tested KANs with fewer than 5 input dimensions and 1000 training points, meaning we don’t yet know how well they generalize at LLM-scale.
- GPU Challenges: There are reports that KANs struggle to run efficiently on GPUs, which could be a bottleneck for real-world adoption.
- Validation Needed: While initial results are exciting, KANs need further testing across diverse AI applications, including NLP, vision, and scientific computing.
Despite these hurdles, the potential benefits are massive:
🚀 Shrinking LLMs → Reducing model sizes could improve sustainability and democratize access to AI.
🎯 Boosting Accuracy & Transparency → Addressing bias, hallucination, and interpretability issues in modern AI.
🔗 More Sophisticated AI Without Multi-Model Complexity → Combining structured precision with deep learning’s ability to handle unstructured data.
Why This Matters for the Future of AI
If KANs prove scalable, they could fundamentally reshape the AI landscape—moving us beyond LLMs to a new class of ultra-efficient models. This could accelerate the rise of Small Language Models (SLMs), Edge AI, and enterprise-grade AI solutions that don’t require massive GPU server farms.
At Dataception Ltd, we’re closely monitoring these advancements, and we’ll be exploring how KAN-based architectures could integrate into Composable AI solutions. Stay tuned for further analysis as this field evolves.
👉 Link to the papers
Code example: https://github.com/KindXiaoming/pykan
Paper: https://arxiv.org/pdf/2404.19756 🚀
📸 Image and code courtesy of Ziming Liu