
Centralised data platforms have been around since the invention of the data warehouse (created last century by Ralph Kimble amongst others) to provide businesses the analytics capability they need. Since their invention, the industry and its associated data, has moved at a massive pace, requiring these platforms to support an increasingly changing and diverse data and analytics landscape.
Even though, during this time, the data platform has evolved (i.e. data warehouse to data lake etc...), many companies with these technologies still wait many months for their analytics deliveries and struggle to bake the breadth of analytics capability into their business.
In this article, I will outline a new approach and architecture to the data platform, called the data mesh, proposed by Zhamak Dehghani (Data-monolith to mesh). It aims to solve the “Architectural Failure Modes”, as she puts it, from existing Data Warehouse and Data Lake architectures to support these requirements. It aims to finally allow data infrastructure to support the whole business with the flexibility and speed it needs.
As multi use-case and business domain, data infrastructure is an absolute requirement for a modern data driven business, companies can spend a lot of time in engineering to cope with the diverse range of Analytics that need to be created. E.g. SQL/Structured, Machine Learning Deep Learning, Advanced Simulation etc…).
Specifically it focuses on the following:
- Data Product thinking – Making the business teams responsible for code, data and metadata, and infrastructure- removing long time-to-market, complex cross team deliveries.
- Domain-oriented decentralized data ownership and architecture - Allowing the business teams to fully own the data and analytics as their “products”
- Self-serve data infrastructure - Allowing business teams to create fully end-to-end deliveries that are controlled and automated to avoid time being wasted on non business value tasks
- Federated governance - A governance model that copes with decentralized business team ownership whilst enabling interoperability and reuse of data and logic. It does this by having the infrastructure do most of the heavy lifting in an automated way.
This article presents some extensions from original the data mesh Pattern and try to address some of the particular failures of centralised data platform solutions I have seen from 15+ years delivering these across the industry.
So, why do Data Warehouse and Data Lake have failures and what are they?
The Industry Challenge
As multi use-case and business domain, data infrastructure is an absolute requirement for a modern data driven business, companies can spend a lot of time in engineering to cope with the diverse range of Analytics that need to be created. E.g. SQL/Structured, Machine Learning Deep Learning, Advanced Simulation etc…).
One major reason for the types of failures outlined in the article (above), is, as different types of data questions need to be asked of the data, different data, technology and algorithm patterns need to be able to be applied to different parts of the data universe as quickly as the business needs them.
This can lead to:
- Data landed but not understood or fit for any purpose other than its original intention, leading to data teams spending time re-inventing the wheel for each new analytics project
- Non-self-service – The business requiring IT and data teams to perform lengthy dev cycles before anything is delivered. (today even short releases can have a massive impact to the business)
- Long on-boarding lead times for new data and especially new technology: e.g. you have implemented a fantastic distributed Massively Parallel Processing (MPP) based data platform but the business now requires lots of simple concurrent requests on small datasets.
- Lack of flexibility – major time spent in performance tuning complex queries on very large datasets because one tried to implemented a one-size fits all technology
"Respondents reported that on average 45% of their time is spent getting data ready (loading and cleansing) before they can use it to develop models and visualizations.”
– Anaconda 2020 State of Data Science Survey
The above response from the 2020, Anaconda survey is a set of challenges that manifests themselves as a result of the above.
Also, a lot of conversations I have with businesses teams tend to be “I just want to ask this specific question on this subset of the data, today, and ask another different type of question tomorrow”. I also tend to see 90% of end-user use-cases are performed on a different 10% (or less) of the raw data stored in a company’s data estate.
A lot has been written about the journey companies have typically taken from Data Warehouse to Data Lake. But the data mesh solves problems that the Data Lake struggles with.
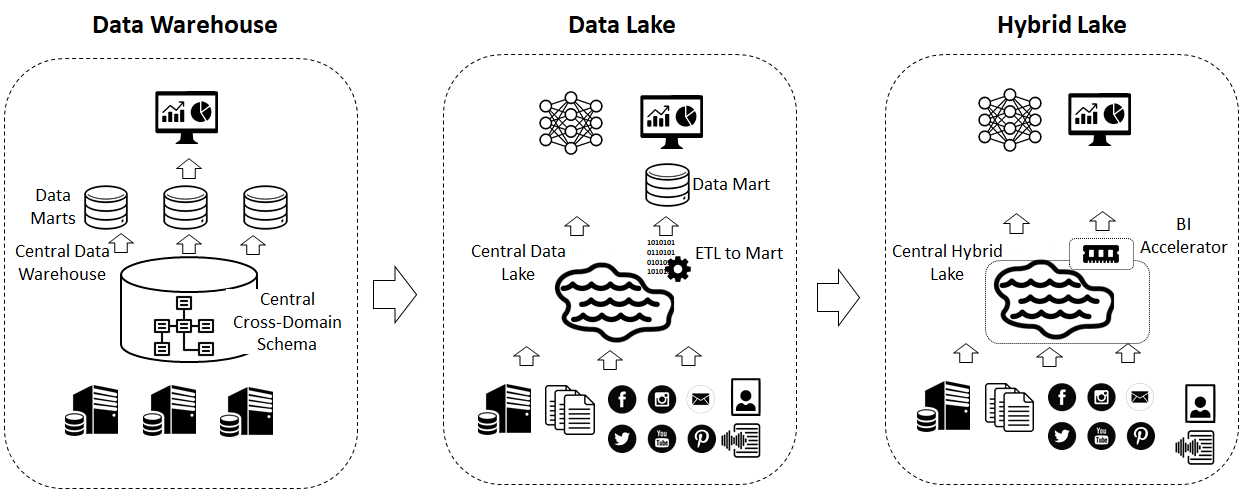
To touch on this journey, companies generally started by building a data warehouse. Which is a central database that allows structured data to be transformed on ingestion into a combined cross domain schema that then serves BI type clients with SQL based queries. But organisations found real challenges with these implementations: E.g. Rigid schemas that have to be defined ahead of time that break when new requirements come in, ingestion and data transformation taking a long time before any business level questions can be answered, only one type of data and processing can be done so move advance questions can’t be asked (AI and ML for examples) and the big one, all of these resulting in high cost to build and run.
As businesses demanded more complex and varied analytics from their data teams, the Data Lake was born. The Data Lake tried and address some of these requirements by promising the following: more scale (many terabytes to petabytes), and the ability to process different data structures (Document, text, hierarchical etc…), different processing patterns, graph, machine learning along with real-time streaming and also the ability to cope with change, in aspects like schema evolution and schema-on-read.
But what typically happened was, as Data Lakes were built, a lot of the use-cases were simply more data warehouse use-cases attempted on the Data Lake technology stack. The Data Lake processing engines (e.g. Map-Reduce and Spark) weren’t built for the query requirements that typically come from BI tools. They were built using a batch orientated architecture i.e. one submits long running jobs that get distributed over a cluster of servers. The calling process waits for the jobs to finish. This works really well for large processing jobs (e.g. processing of large datasets), but not for the execution of lots of small jobs. Even though Spark has some tricks to speed this up (e.g. being in-memory, Map Reduce – largely disk based) one couldn’t reliably connect a BI Tool to a Data Lake.
This is because, one dashboard may execute many concurrent queries on small datasets, that all require quick turnaround otherwise the dashboard user is sat waiting for the page to refresh. This was typically solved by having a database sat in-between the Data Lake and any BI tools to cache the data and provide the fast querying capability.
Also, another road many companies took was to spin up massive programs that tried to ingest all their data onto the central lake without understanding what the data was to be used for.
This resulted in lengthy and costly infrastructure with ingestion projects that lasted months and didn’t actually deliver any significant ROI or even support the businesses wide range of analytics requirements.
During this time public cloud started to be adopted which provided cheap on-demand compute and storage. This gave birth to a new generation of Data Lakes and Data warehouses on the cloud that could support different data structures and scale easily and cheaply because they could separate compute from storage. This step has also given rise to the Hybrid Lake, which is a cloud-based Data Lake solution that includes a component that allows one to connect to the Dashboard directly to the core infrastructure. I call this a BI accelerator and includes aspects like a caching layer that replaces the database in the original lake.
This evolution has greatly improved life but there are still key challenges:
Challenge 1: Truly self-service is still difficult to achieve.
The Lake/Hybrid Lake is still very much an engineering lead solution. Say a business user wants to do a quick bit of analysis on some data in the lake with analytics that aren’t catered for by the technology, then they will want to spin up a data analysis tool on their desktop and try to extract the data from the lake into it. This could take days or weeks in raising tickets, finding, and understanding the data, splitting it up into digestible pieces that their laptop can handle. So, the lake in this case has become an expensive file system (I have seen this a lot).
Challenge 2: Siloed and hyper-specialized ownership
The pipelines are built for their specific use-case which means change becomes expensive and time consuming and re-use is difficult. So, what ends up happening is, many complex very specific pipelines are built that have a high operational overhead and every new one is built from the ground up. Parts of these pipelines are handled by different teams e.g. ingestion by the ingestion team, core features by the platform team, and the business teams all waiting for these to complete their tasks before they can use the platform. Also, one sees stretched data engineering teams trying to solve deep domain problems that they don’t have the knowledge of leading to frustration and time sapping, back and forth conversations with business teams.
Challenge 3: Centralized and monolithic
There is still a focus on getting data to the central infrastructure, be it on public cloud or on-prem, and woe betide anyone trying to bridge the two. This can still take a long time and result in data project managers presiding over many long running ingestion tasks whilst getting shouted at by their business asking why their insight hasn’t been delivered.
Challenge 4: Lack of re-use and duplication of pipelines and data
One also, has to glue together or implement separately, different processing solutions for the different use-cases. E.g. IOT pre-aggregation and graph-based use-cases will use different engines, data structures and query semantics. So, this will mean a lot of work for the engineering department to bring together or the rise of shadow IT, as each area of the business goes away and builds their own.
There is no prescribed data architecture or curation approach. Data is still scattered amongst the storage on the lake and in BI; Data Scientists spend time to find, understand and use it. Data needs to be governed but also needs to evolve as use-cases change and new ones come about.
Data Product Thinking
In order to solve these, the first thing is, to start thinking about delivering data products rather than just data, pipelines/models or dashboards.
DJ Patil defines a Data Product as “… a product that facilitates an end goal through the use of data”.
The original article offers data-as-a-product as a way of encapsulating the data and structures for a domain and use-case. Which means, one creates datasets just for the business use-case the product was intended to solve. These could be tables or other structures like graphs or collections of documents/key values etc...
The Enterprise data mesh takes takes this further by including the data and all the end-to-end analytics components as part of the product. This is called a data product and actually can provide much more value. If one is providing federated governance around the data then if this is extended to the data tools and applications as well, one avoids the risk of data and the applications becoming disjointed and out of synch (version mismatches etc…).
The way I think of it is, if the data product is a song (a piece of insight from a customer driven use-case), then one needs a digital music player to play it (the underlying technologies, BI tool, database etc… - note a data product can contain more than one technology) and a music eco-system in order to browse, play and contribute to (this is where the data mesh comes in).
Traditional data platforms aren’t geared up to support this type of approach. To understand where the challenges lie let’s do a quick dive into a typical data platform.
They are generally split up into three layers.
Ingestion - Getting data onto the platform, including transformation, data quality etc...
Transformation / model - Building the core of the analytics models and pipelines, including data wrangling, pre-processing and transformation for the models to be able to consume the raw data.
Business visualisation and decisioning - Where the actual business benefit gets realised by the business teams and includes “Management friendly” Dashboards/ reports and integration to decisioning systems e.g. e-commerce websites for recommender engines.
When new analytics projects are implemented there are usually different teams that have responsibility to deliver specific work and artifacts in each layer of the platform.
- Source system teams, to locate the source data.
- Ingestion teams to get the data into the platform’s storage areas( nowadays, typically blob storage on the cloud).
- Analytics teams then typically build the pipelines and models who finally hand them over to business decision makers who consume management friendly visualisations and have teams to integrate the output into decisioning systems.
The upshot is that each piece of insight is actually a disparate set of software and data tasks and deliverables built by different teams.
Typically, it takes 2 months to deliver complete dashboard from scratch and 3 months for an ML model
Some of the reasons for the long time frames are:
- Extended amount of time to get analytics to the business so that they can make decisions.
• This time can be up to, 2 months for a complete dashboard and 3 months for an ML model. Because of aspects like team hand-offs and back and forth communication exchanges between them - Complexity is increased:
• Technology - typically the stacks can differ between each of the stages, meaning a lot of time and effort is spent “gluing” together disparate technologies from open source and vendors
• Organisation - the central platform teams can swell to large sizes and there needs to be domain experts within many of them that understand all business lines. All of which can be costly and difficult as the market is clambering for these types of resources
The data mesh solves these challenges implementing data product orientated approach. i.e. Delivering wholly encapsulated analytics packages of software and data by the actual business team that has the business stakeholder.
An important aspect is that they do this with little no help from central teams. If one achieves full self-service by the business teams, this massively reduces time-to-market of the delivery of each piece of analytics insight.
Challenge 1: Truly self-service is still difficult to achieve
Solution: Enable the teams that own the use-case to build the whole pipeline and analytics product rather than rely on other teams
Domain Driven Design
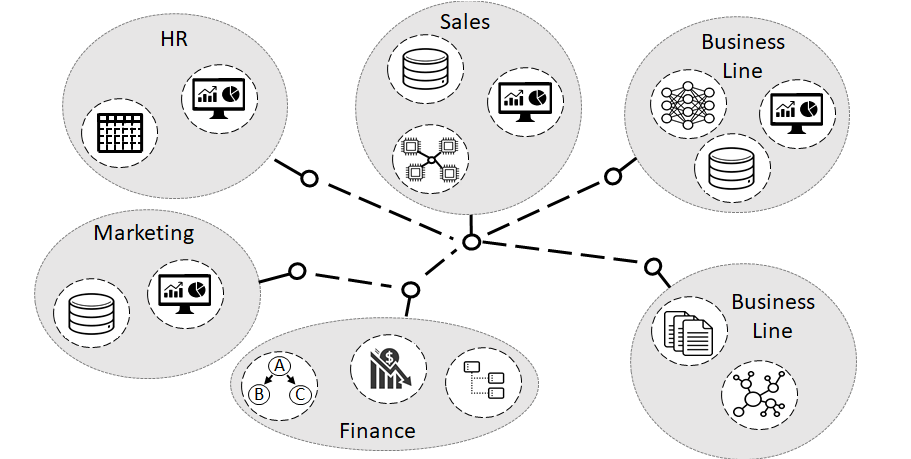
The mesh approach also aligns a product to a domain. Whereby a domain maps to a business area in the organisation (following a Domain Driven Design design method)
Each product is wholly created and owned by a domain. Even data that is surfaced from the existing IT estate is created as products in the data mesh an owned by domain
Data Products are built on top of other products in the same domain but could also could bridge other products in different domains
To really focus on a data product for a domain one creates specialist datasets and logic that supports a specific customer use-case rather than trying to build cross domain / use-case central schemas and data models. If this is done correctly then the organisation needs only scale out the business analytics teams, and can keep the central platform teams small and efficient and only focussing on business neutral services that support the business team’s creation of data products.
This gets around the siloed and hyper-specialized ownership aspects of the Data Lake as only the business team deploys the ingestion, pipeline and visualizations / decisioning parts of the analytics delivery. An important aspect is that they do this with little to or no help from central teams. If one achieves full self-service by the business teams, this massively decreases time-to-market of the delivery of each piece of analytics insight.
Challenge 2: Siloed and hyper-specialized ownership
Solution: Build only use-case specific artefacts that are owned by the business domain teams .
I have talked about data products numerous times, but what makes up a product?
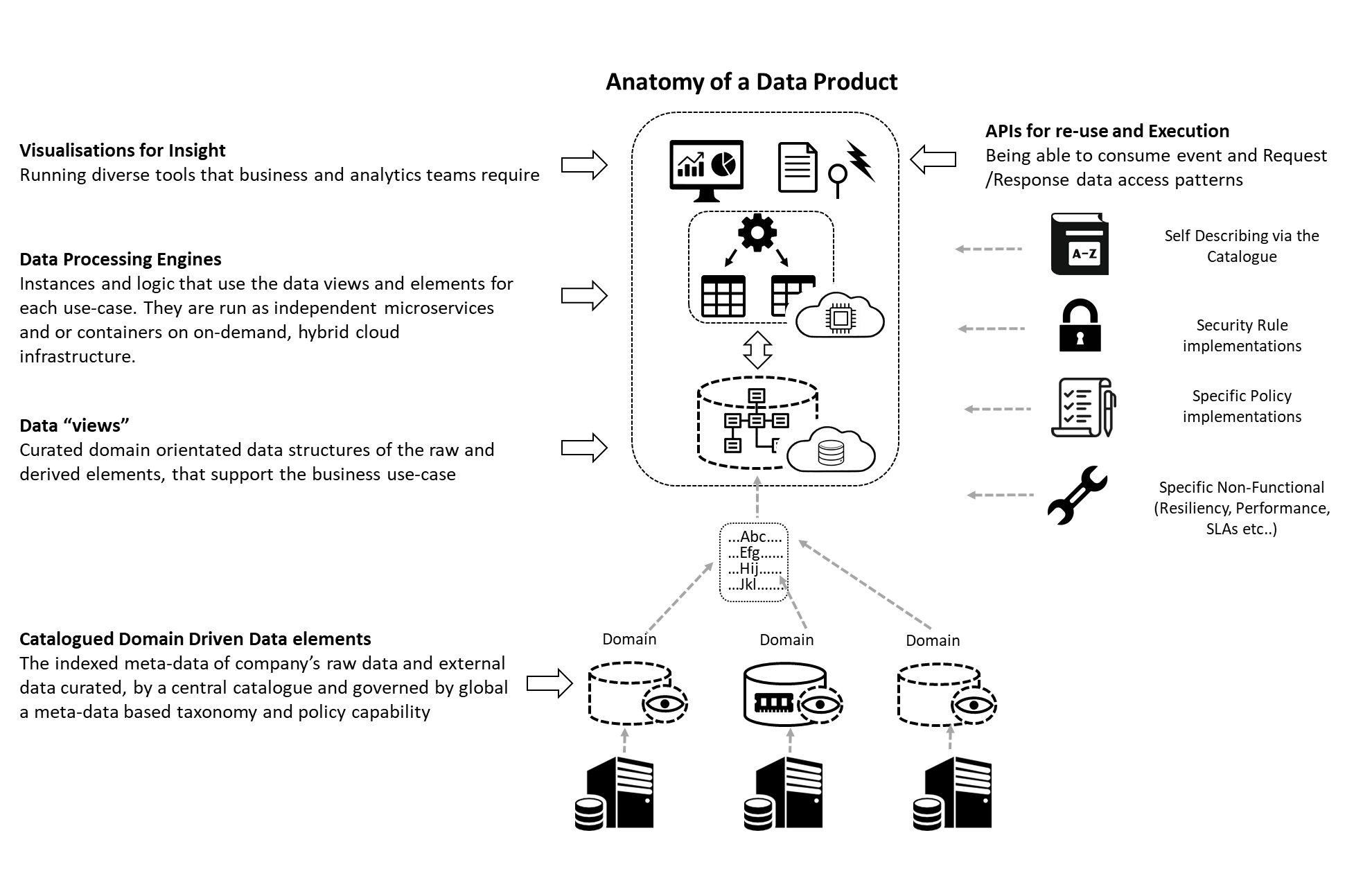
Products are delivered as a wholesale package – as one would do with a software application and subject to consistent application of deployment and life-cycle and security and policies.
Typically, most data platforms cover datasets, which are important but, it’s also key to define the characteristics of a data product as more than just datasets.
A data product can only be called such, if it has the following qualities.
Discoverable: You need to be able to find it easily
The infrastructure needs to include a “developer friendly” catalogue that can be used by analysts, data engineers and data scientists as part of the development cycle. It indexes all the product attributes, not just data but other business meta-data about all the artefacts.
This addresses the “re-use” aspects of the problem by allowing teams to find and build upon existing work which again, massively speeds up time to market of the delivery of each product.
Challenge 3: Lack of re-use and duplication of pipelines and data
Solution: Allow analytics teams to easily find and understand existing data products across the whole platform
Addressable: Meaning it must participate in a global eco-system with a unique address that helps its users to programmatically find and access it.
The catalogue includes a global unique id and description of the product and artefacts and a way to execute
Each product each artefact includes a globally unique resource identifier so as to be able to be addressed, located and executed
Self-describing: One needs to understand it (business as well as technical structure) without going back to the domain teams.
Again, the product publishes all business and technical data about it in the catalogue. Typical artefacts that are sourced from the product include table/schemas/structures, metrics from BI source files etc…
Secure: Be able to be accessed security with global policies
All the artifacts are governed by global role-base-access, GDPR, Info security, data sovereignty and other policies. This includes not just the data but the execution of the processing engines and access to the visualisations.
Trustworthy: Providing data provenance and lineage and data quality from the owner
All data products publish their access to data and other products so one can follow the line of processing across the Mesh and see where it originated from.
Interoperable: Be able to reuse, correlate and stitch them together across domains for new use-cases
Products can be built on other products via well published end-points and share views, connections and other artefacts.
Enterprise Data Mesh
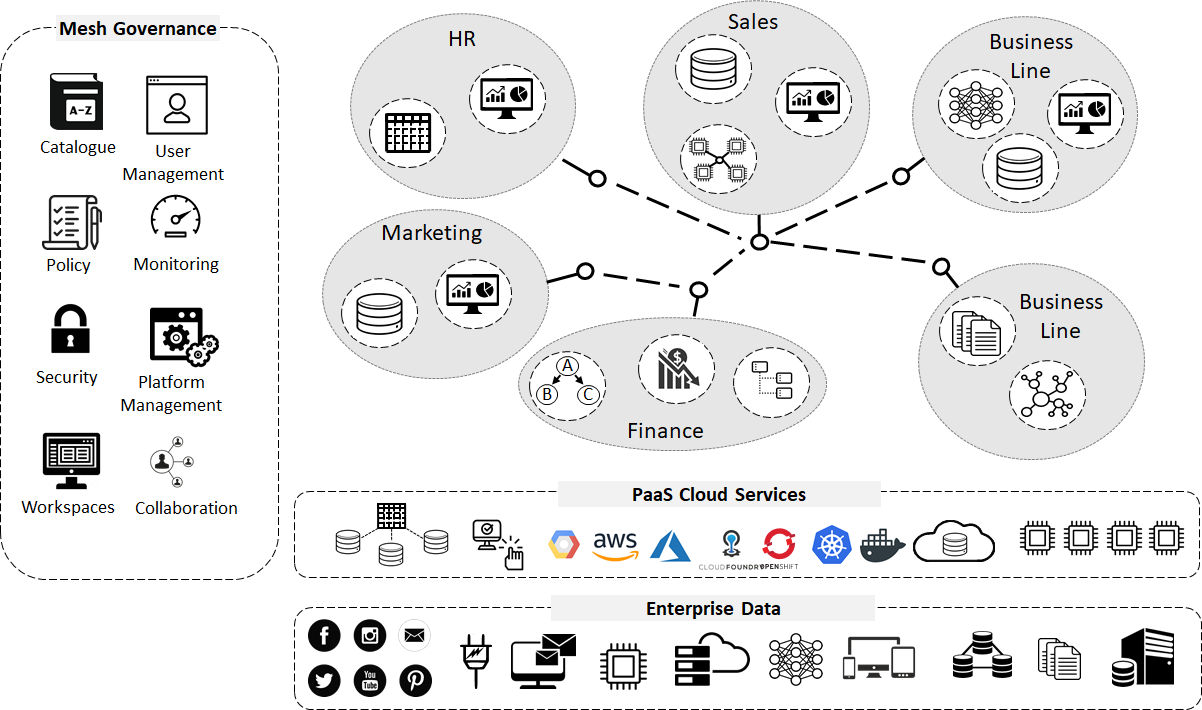
To support the building of data products, one deploys an Enterprise data mesh infrastructure. Which is a self-service collection of services and allows business teams to create, share and build data products in a totally self-service way across the whole business.
These services are delivered as a PaaS (Platform as a service) and have a common execution and governance i.e. one they are all controlled using the same policy and security modes and the services can all be accessed using a common set of APIs
One major aim is to shrink the lead time to create and update new data products. Most (if not all) of the time should be spent by data and analytics creators on creating the actual logic, models, derived data and visualisations, not on ancillary tasks such as ingestion, understanding the data and platform engineering tasks common on lake and warehouse infrastructure.
One way this is done is, to avoid duplication of effort, provide the business analytics teams access to tools and services to bring on data and build truly end-to-end analytics without needing to constantly go to the central platform team for tasks. So, in effect this becomes data infrastructure as a platform rather than a data platform that requires central teams to build customer use-cases on. It enables teams building those data products to build new data products quickly and efficiently and with tools that they are familiar with, whilst providing a common set of architecture and skills framework.
It provides business user driven workspaces with a variety of user driven technologies (both back and front end) that can be spun up in safe sandboxes (cloud VMs or containers). The artefacts have central policies applied and easily searchable global meta-data about all the relevant other artefacts (datasets, dashboards, features etc.) that could be used to build the analytics.
Data products deployed on the data mesh share a lot in common with microservice architecture and are built on top of such. Data products run a composition of containerised components and microservices on either Function-As-A-Service or Container orchestration infrastructure. A data product only really qualifies as a data product if it can be found, executed and re-used. So, it needs to have a discoverable and executable endpoint that is found via the catalogue. Most importantly, it needs to be interoperable so that it can be orchestrated as part of other data products.
It’s important that a data infrastructure platform stays domain agnostic and as infrastructure. E.g., when you’re working on a component of the core infrastructure and you realize that you need to have some domain knowledge to solve a problem, there is a good chance you are careering towards building a monolithic data platform and this is something that needs to be avoided.
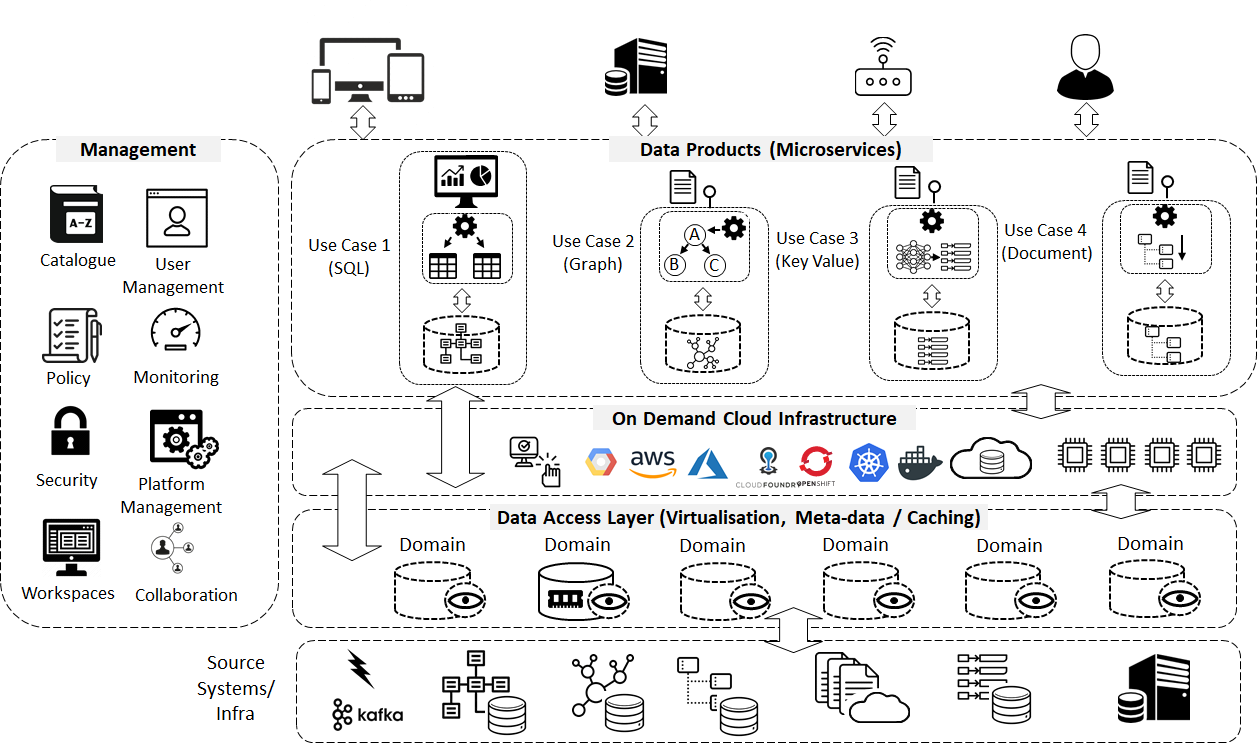
Lets do a deep dive into the technical architecture.
The mesh implements a distributed data and execution architecture but with centralized governance and standardization for interoperability. This is supported by shared and standardised self-serving data and cloud infrastructure.
The technical architecture is broken down into three layers.
Data Product layer – A distributed self-service design and run-time environment that allows users to run data products as self-contained units.
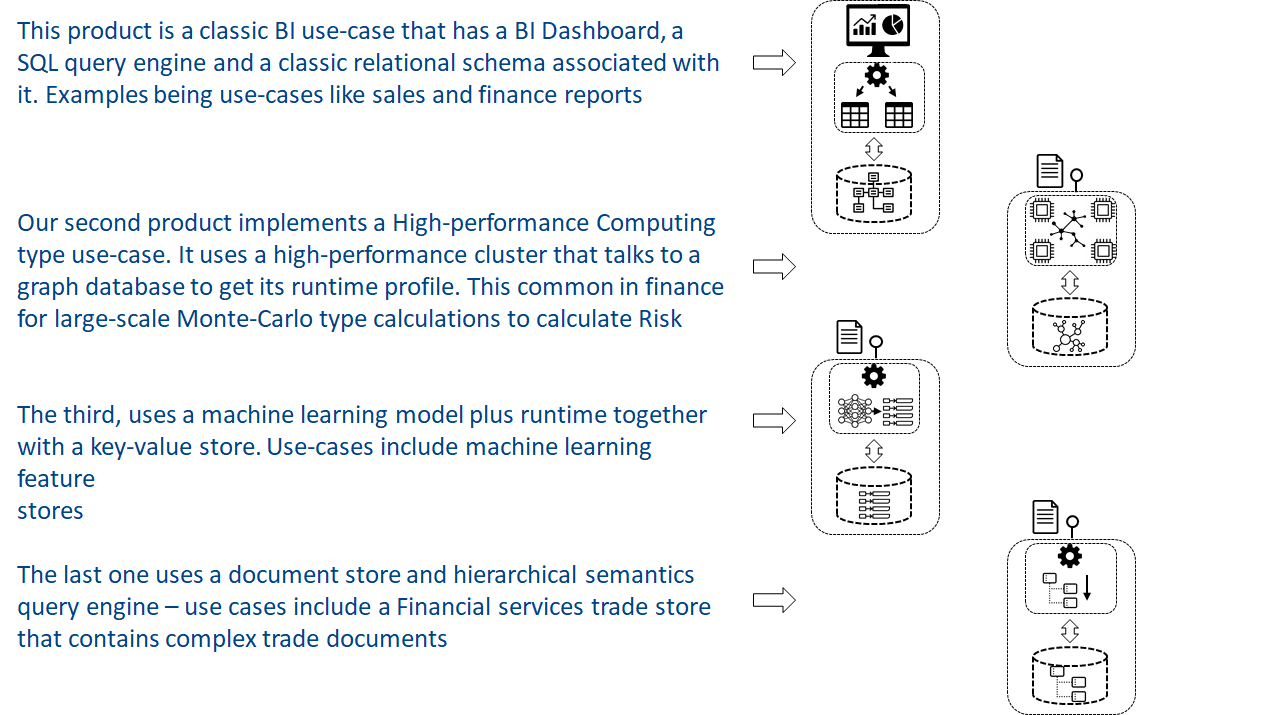
As an example, (the diagram below)– we have 4 data products.
All products need to self-publish into the catalogue along with meta-data which enables fast discovery by consumers browsing as well as analytics and data product creators. This avoids the “Swamp” effect, whereby artefacts are added to the infrastructure and either lost or the meaning has disappeared with a member of staff that has left the organisation long ago and took all the knowledge with them.
The Cloud Infrastructure layer - Allows users to spin up the data products as a collection of long running and/or ephemeral container-based components from templates. They implement a wide variety of data technologies in a cohesive way across a heterogeneous global hybrid cloud estate.
It provides single compute units and clusters, for distributed processing engines like Spark, Dask etc… It is self-service so people can use these clusters at a touch of a button without needing to care about actually operating the infrastructure i.e. without needing to get into container software APIs and complex configuration. It includes cost limits set by the business to avoid massive bills. It is delivered across all cloud providers and on-prem infrastructure provided by software like Docker and Kubernetes
Challenge 4: Centralized and monolithic
Solution: Allow the deployment, running and management of independent data products as containers or data microservices.
It also provides an abstraction into data infrastructure on the cloud. So, the user can spin up whatever service, database or NoSQL system they like without having to know any details of the configuration.
The layer also provides aspects like data product versioning, source control and life-cycle management.
The mesh allows a data product to be created from a system of data product templates that users use to build their data products in “project” workspaces.
Templates are made up of components that are configurations of technologies like databases, BI tools (Web and desktop based), processing engines, datasets, configuration, frameworks, web servers etc.
The components include the relevant type of data processing for the specific use-case. e.g. A SQL engine for BI queries, a graph engine for graph analytics, machine learning model frameworks (e.g. Python/ scikit-learn, R etc.).
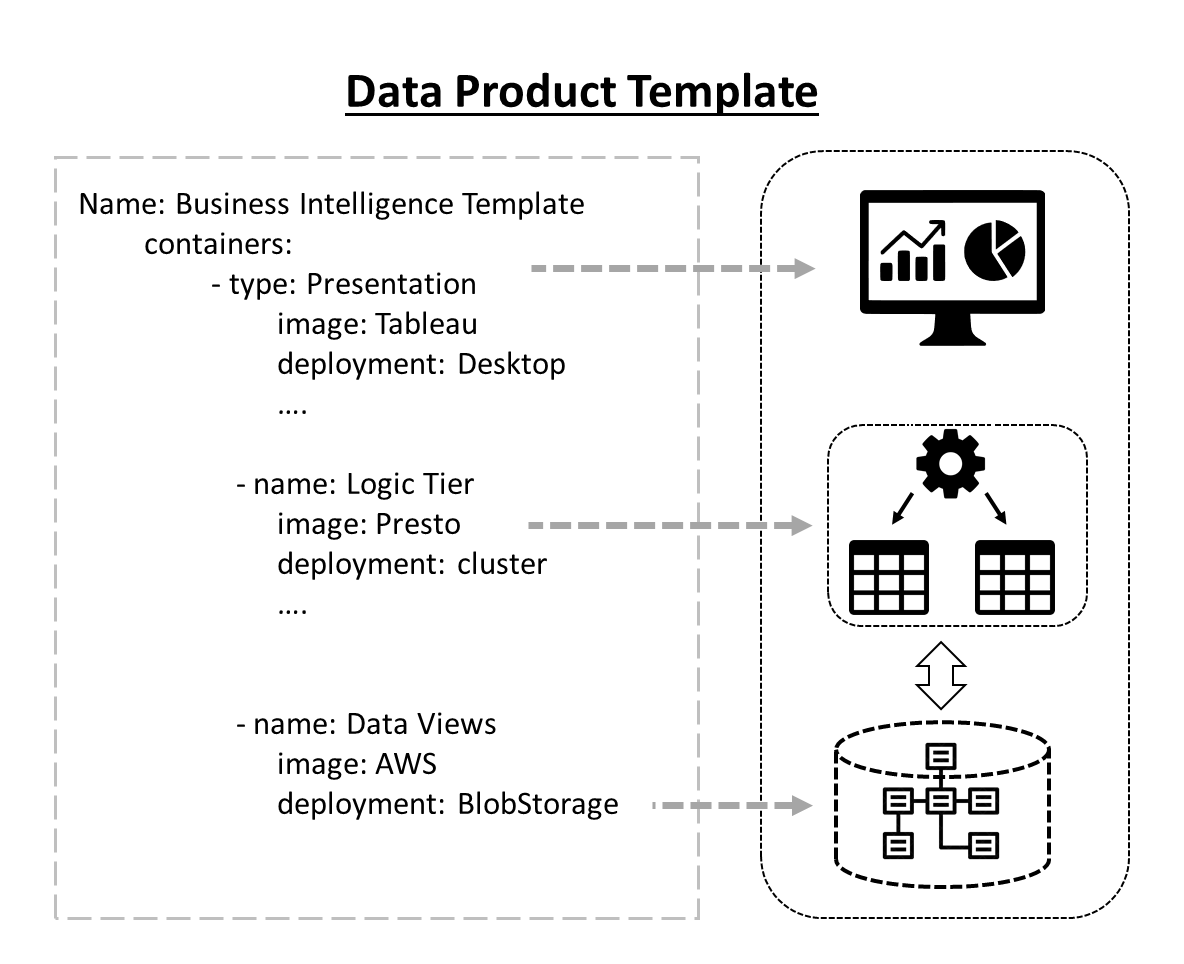
The template is stored in a computer readable configuration in the mesh that can be deployed by the infrastructure or built upon to create a new data product.
Templates could include instances of data pipeline tools like Alteryx, Apache Beam, Dagster, or databases like RDS on AWS or distributed processing frameworks like Spark or Dask, BI tools like Tableau or Apache Superset or even full solutions like Databricks or Sagemaker. It’s important to support whatever kind of technologies the business wants to use in the language they choose. If a user needs a new technology then it’s easy to deliver as a container or desktop app through a central governed platform on-boarding process. This means that we are still providing central services but they are also globally governed and interoperable.
The Data Access Layer – this surfaces all relevant data in the estate as close to raw as possible through a data virtualisation component. The data is indexed in a catalogue alongside business definitions and meta-data that describes the data
It includes connectors and a virtual view of all the data in the estate even if they reside in systems and databases, cloud storage, SAN and file systems and others infrastructure
The virtual views are surfaced through a metadata cataloguing component that surfaces information on all the different artefacts for people to be able to find easily. It is governed, not only by providing additional information about the artefact, but also by allowing standardized processes around, aspects like access, security and naming for attributes.
The way I think about it is a concept of “Curated Views”. This essentially allows users to have their own views of their data on top of their own cloud storage buckets. People have their own sandboxed cloud storage, that could be on-prem or on a public cloud provider or even scraped from a web-site. They create and land interact with the artefacts as part of a project that will ultimately become a data product. Any derived datasets are also catalogued and indexed in centrally so anyone (given the right permissions) can find them.
The data and metadata are accessible through a cloud abstraction layer, using the same governance layer that is used to apply access to services in the infrastructure and data product layers. It's important that the views are "synchronised" to the rest of the system i.e. the schema and meta-data is known and controlled by the management layer to stop the fragmentation that occurs using disparate components. This means when data or schemas change they are reflected in the views.
A key addition is data virtualisation which surfaces data sets that are external to the platform without creating time consuming data ingestion tasks.
Data Virtualisation
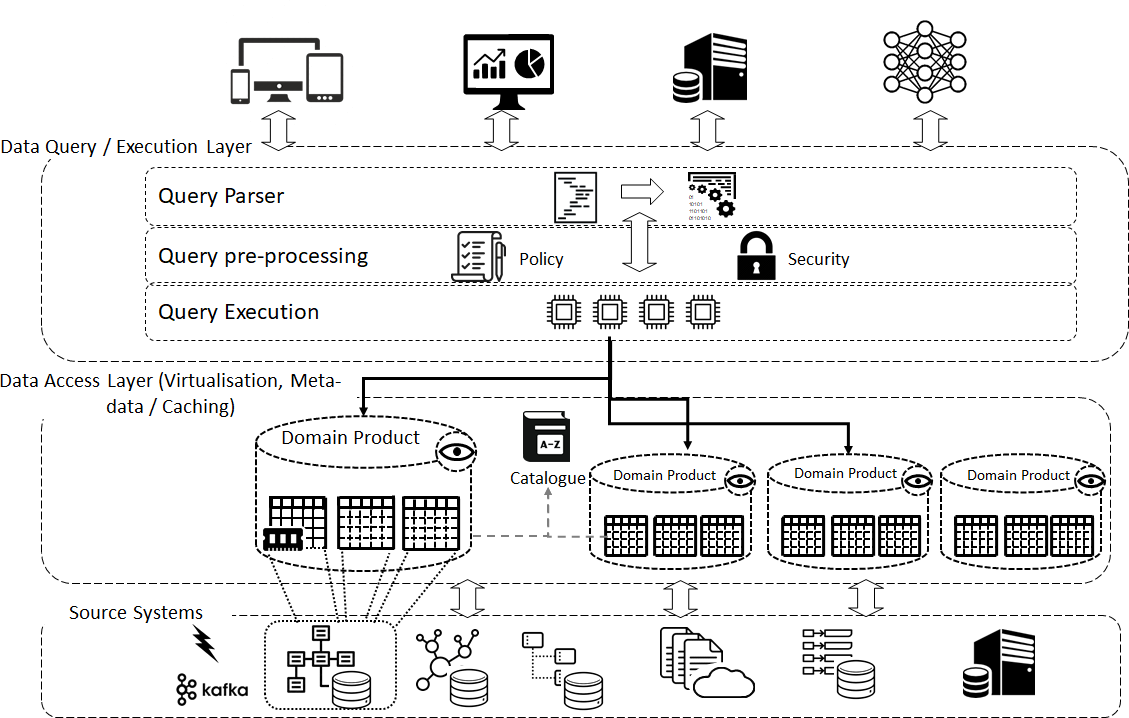
The data mesh, in the original article, takes a different approach to the data connectivity between products. It talks out the concept of data ports, which are a means of accessing data by the data product exposing well defined interfaces e.g.SQL, REST etc... for each of the products datasets
For the Enterprise Mesh this is done via Data Virtulisation. Each dataset inside a product can be accessed through a common query layer that implements multiple query semantics e.g. SQL, Graph, Document, Key Value etc... This allows easy access to data as well as being able to expose data that lives outside the mesh (i.e. in he rest of the I.T. Estate) without the need of physically copying.
To dive into this further, as the diagram shows, data products have virtual views of data that are composites of the raw data in the source systems. They are implemented in the appropriate technology that is required for the product e.g. relational for random access SQL type use-cases, graph models for graph-use cases etc.
The Query layer stitches together queries across the domain “Views” and the catalogue provides the list of attributes (backed by business descriptions and other meta-data) that allows the analytics builders to pick and choose for each use-case. It also applies security and data policy at query time which avoids having to build separate data stores to support requirements contained in GDPR and data sovereignty regulations.
Data can be cached for large datasets or for systems that have sensitive or slow data access, but it’s important that they remain “synchronised'' i.e. one wants to avoid unnecessary copying of data that could result in it becoming out of sync with its source transactional system. It also shows aspects like usage (by all teams), lineage across the organisations, versioning and life-cycle events.
All this is needed in order to provide all the services necessary for the business teams to create data sets in a completely self-service but controlled way.
It’s important that this layer can surface addressable polyglot datasets from all types of data source without long ingestion task time-lines. The layer supports querying and returning result sets across a variety of data technologies. The obvious one is SQL based relational and data warehouse technologies, but it must include others like graph and document-based query semantics and result sets. Most data lake solutions struggle to do both in a consistent and self-service way.
The catalogue provides central discoverability, access control and governance of distributed domain datasets. This supports self-publishing of artefacts from a wide variety of cloud data storage options and allows domain data products to choose the relevant polyglot storage option for usage.
Summary
So, to summarise and bring together what we have discussed.
We started with the journey and some of the underlying aspects of current data platforms: centralized, monolithic, with highly coupled pipeline architecture, operated by silos of hyper-specialized data engineers and data scientists. We looked at the building blocks of data mesh as a self-service infrastructure; federated data products development, oriented around domains and owned by independent cross-functional teams who have their data engineers and data product owners embedded in their teams. All this using a common data infrastructure as a platform to host, prep and serve their insight and data products.
The way to think about this new approach is to treat domain orientated data products as a first-class concern and the tooling and pipeline as a second-class concern - an implementation detail. Steers away from the centralized data lake approach to a data ecosystem of data products that play nicely together.
The key to success for self-serve data infrastructure is decreasing the time-to-market to create a new data product on the infrastructure. The infrastructure needs to provide a fully automated set of services that can be used wholly by the business teams to build “stand alone” data products. These must include, the data ingestion through configurations and scripts, data product creation scripts to put scaffolding in place and auto-registering a data product with the catalogue, etc.
Cloud infrastructure plays an important part as a backbone to reduce the operational costs and effort required to provide on-demand access to the infrastructure. Data virtualisation also needs to be implemented to further speed up data integration.
I hope this article has shown how the data mesh infrastructure goes beyond Data Lake and Hybrid Lake solutions that enable support of many business use-cases, in a cost effective and flexible way.
As always, comments and feedback are really welcome and even if you want to know more, drop me a line by using social media.