
The modern data ecosystem needs strong, proven foundations. For me, this journey started years ago with my first data product-oriented solution. Long before the advent of data mesh and during the rise of Hadoop, I designed and built this solution with a crack team around 2014. Though it has undergone many iterations since then, the fundamental approach and architecture have remained steadfast and proven.
The Business Challenges
The solution was initially built for a bank facing significant business challenges:
- Management Information (MI) & Reporting Issues: Data was located in disparate systems with a variety of data models. Accessibility was highly restricted, and there were no standardized metrics definitions or MI production processes.
- High Operational Costs: The organization employed 250 full-time equivalents (FTEs) to produce MI, resulting in large costs, operational risks, and significant data quality issues due to stale data.
- Inefficiency and Compliance Risks: The bank struggled to produce the required level of MI, leading to fines, errors, and high costs due to inefficiencies.
The Technical Challenges
To address these business issues, we tackled several technical challenges:
- Complex Integration Requirements: Integrating 450 systems and data from 30 business areas, catering to 10,000 operational users, required both real-time and batch processing capabilities.
- Scalability and Performance: Handling 30-50TBs of data with complex metric logic, delivering on-demand responses to hundreds of queries per second at a scale of around 50 billion rows.
- Inadequate Existing Technologies: At the time, Apache Spark was at version 0.9, and traditional enterprise data warehouses (EDW) or data warehouses couldn’t support these requirements effectively.
Business Benefits
The solution provided substantial business benefits:
- Regulatory Compliance: Improved control over the environment, ensuring adherence to regulatory requirements.
- Enhanced Measurement: Enabled increased measurement across the enterprise with approximately 2000 metrics in scope.
- Revenue Generation and Cost Reduction: Identified opportunities for revenue generation and cost reduction.
- Operational Efficiencies: Achieved potential operational efficiencies and cost reductions through automation, reducing the need for 250 FTEs, saving approximately $2M per year.
The Solution
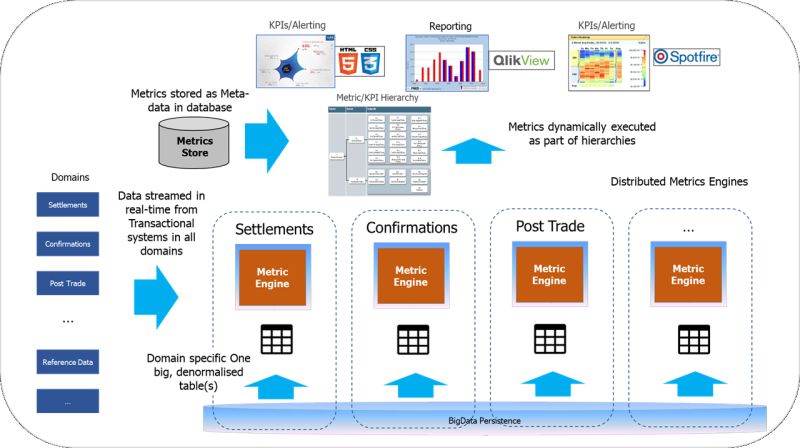
The solution was a distributed metric platform capable of executing thousands of metrics in real-time on streaming and historical data. It handled 120 million daily updates across 30 domains, with an average table size of 1.4 billion rows.
Key Aspects
- Metric Engine: Executing metrics directly from one big table of raw data (one per domain) using standard in-memory relational algebra on billions of rows through a JDBC interface.
- Graph-Based Engine: Executing a directed graph of dependent metrics, similar to how metric layers function today.
- Metric Catalogue: Allowing browsing and re-use of metrics.
- Decentralized Data Models: Metric engines were spun up for new use-cases with their own datasets, eliminating the need for a centralized EDW and supporting flexibility and change.
- Hadoop Integration: Used as an archive, with engines importing their datasets into memory from Hadoop upon startup.
- Batch and Streaming Capabilities: Supported real-time joining of event data with large tables.
- Sophisticated Versioning and Indexing: Utilized fast append-only data structures and multi-version concurrency control (MVCC) to ensure zero data loss and minimal latency.
Mapping Business Needs to Technology Capabilities
The approach seamlessly mapped business needs to reporting and data needs, ensuring that technology capabilities were aligned with business requirements. This architecture has been refined over the years, incorporating lessons learned and advancements in technology.
Conclusion
Implementing such robust solutions with a clear understanding of business challenges and technical requirements can significantly advance the architecture and provide high ROI for customers. It also future-proofs the ecosystem, ensuring adaptability and scalability. This journey has laid a strong foundation for the modern data ecosystem, proving that with the right approach, organizations can achieve remarkable operational efficiencies and business value.